Hi 👋, I am a PhD Student at the University of Maryland, College Park, currently on both the industry and academic job markets. I work on human-grounded generative AI — systems that don't just generate text, images, diagrams, and video, but reason about the people, purposes, and worlds behind those outputs. I am advised by Prof. Jordan Boyd-Graber in the Department of Computer Science.
My research swaps the field's usual target — fluency and similarity — for human utility, across three threads: inferring intent, expertise, and mental models from how people naturally express themselves through implicit and explicit actions (edits, comments, critiques); maintaining coherent multimodal world models of physical and social state across long interactions; and turning dense scientific papers and figures into faithful, audience-aware diagrams, slides, and explanatory videos.
During my PhD I worked with several research groups. I was a Student Researcher at Google Research, hosted by Yiwen Song and Yale Song; spent three summers at Adobe Research; and spent a summer at Microsoft Research Redmond, hosted by Jennifer Neville and Jay Stokes. I have collaborated with Prof. Rachel Rudinger and Prof. Tianyi Zhou on human-centered evaluation.
Before starting my PhD, I was a Research Fellow at Microsoft Research India with Monojit Choudhury and Kalika Bali, and I completed my MS at IIT Kharagpur with Prof. Sudeshna Sarkar and Prof. Pawan Goyal.
Feel free to reach out if you're interested in research collaboration!
Research
I build AI that infers the hidden context behind what people do — their intent, expertise, and mental models — and uses it to generate artifacts judged by whether they actually help, not by how closely they mirror a reference. My dissertation proposal, From Fluent to Useful (ACL 2026 SRW), lays out this agenda in full; the research statement gives the longer version.
AI for scientific communication4 papers
Turning dense papers and figures into diagrams, slides, and videos that are faithful, audience-aware, and useful for real understanding.
Helping Figures Tell their Story! Paper-Grounded Video Generation Explaining Complex Scientific Figures arXiv 2026
Scientific figures compress complex pipelines into a single canvas, yet understanding them requires paper-grounded, step-by-step narration aligned with visual highlights — a capability missing from current video generation systems and benchmarks. We introduce paper-grounded figure-to-video generation: producing narrated, region-grounded walkthrough videos from a figure and its paper. We propose MINARD (Multimodal Interpretation of Narrated Architecture via Region Decomposition), a pipeline that generates paper-grounded narrations and sequentially grounds them to figure regions, and release FigTalk, a benchmark with new sequential and component-level grounding metrics. On FigTalk, MINARD generates human-like, paper-faithful narrations and outperforms existing approaches on narration-conditioned spatial grounding in both automatic and human evaluation.
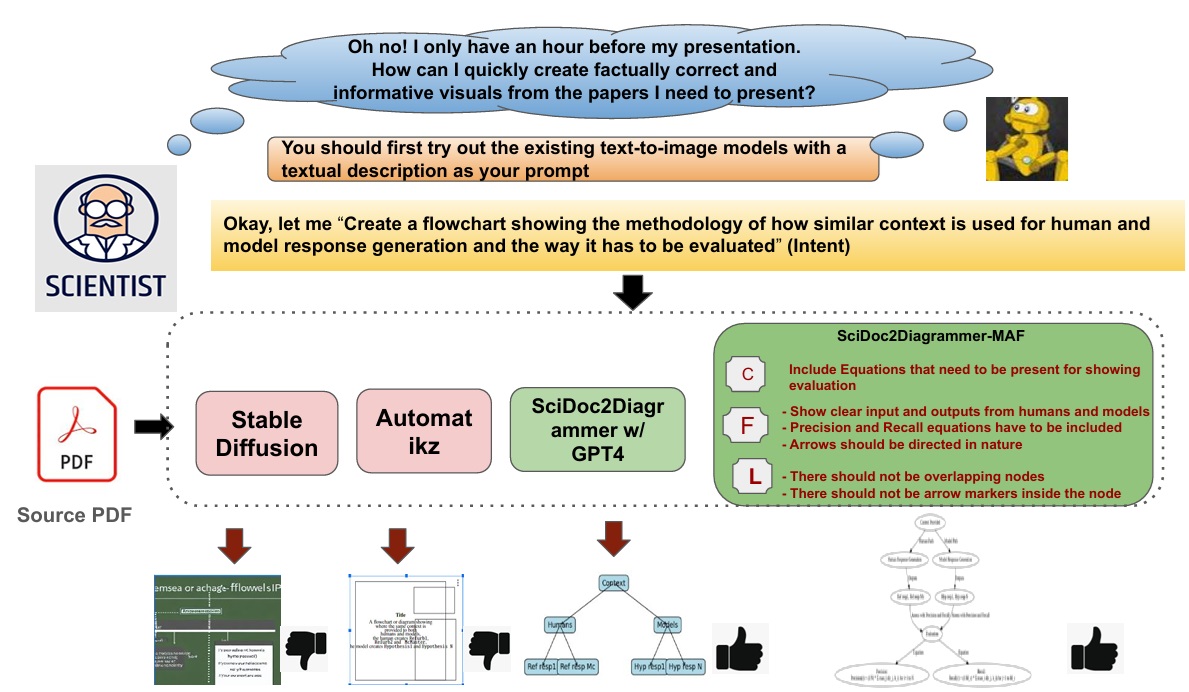
SciDoc2Diagrammer-MAF: Generating Scientific Diagrams from Documents via Multi-Aspect Feedback Refinement Findings of EMNLP 2024
Automating scientific-diagram creation from academic papers can streamline tutorials, presentations, and posters. Current text-to-image models struggle to produce accurate, appealing diagrams from long-context inputs. We propose SciDoc2Diagram — a task that extracts relevant information from papers and generates diagrams — with a benchmark, SciDoc2DiagramBench. Our pipeline generates diagrams from user intentions via intermediate code generation. Because initial drafts were often incomplete or unfaithful, we add Multi-Aspect Feedback (MAF), a refinement strategy that substantially improves factual correctness and visual appeal, outperforming existing models on automatic and human judgments.
Presentations by the Humans and For the Humans: Harnessing LLMs for Generating Persona-Aware Slides from Documents EACL 2024 Oral
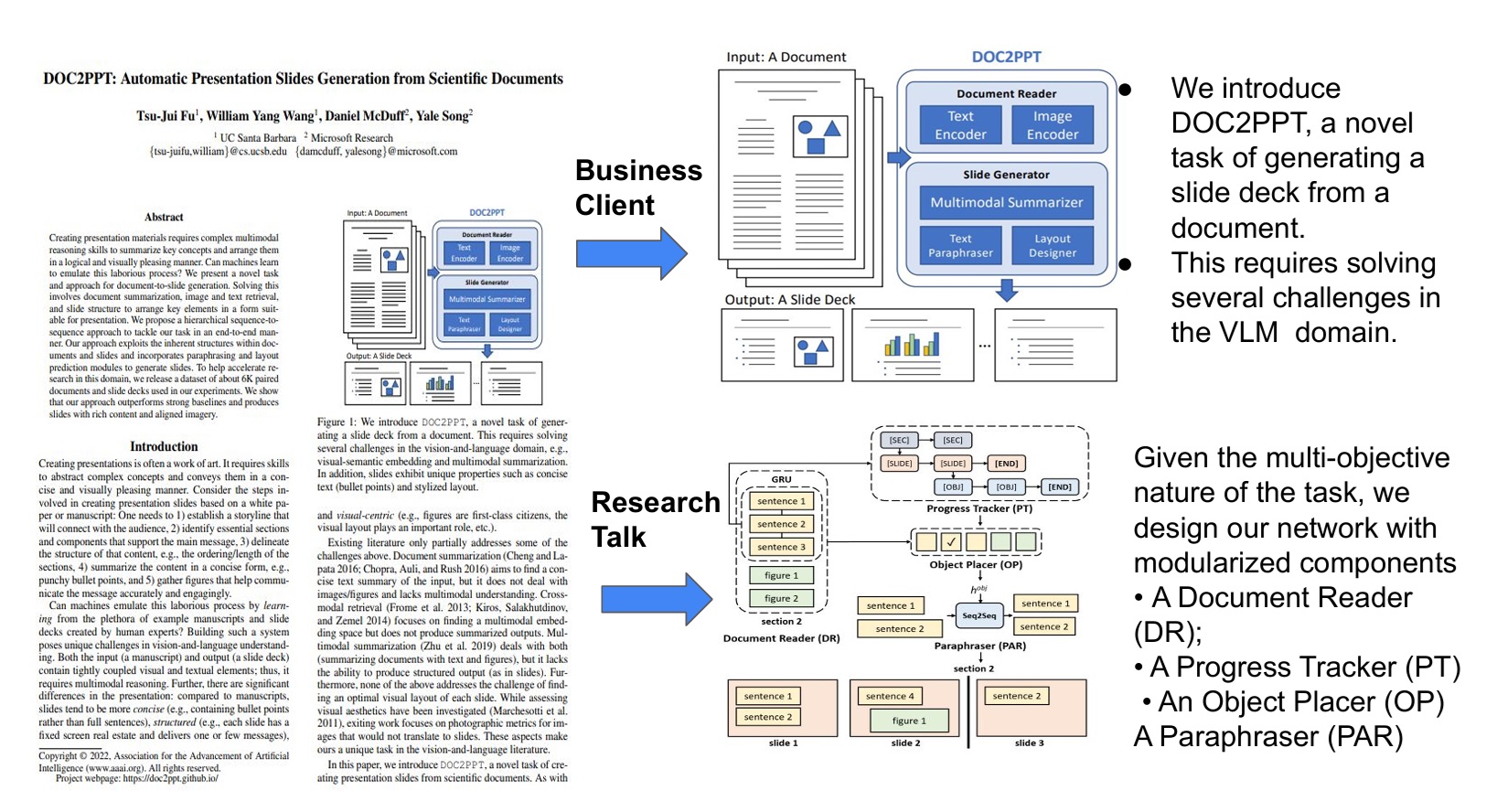
Papers and slides are two representations of the same information, but both take substantial work to prepare. Prior document-to-slides efforts ignore the need to tailor a presentation to the audience's persona or the talk's duration. We introduce end-user-specification-aware document-to-slides conversion: starting from the SciDuet dataset of paper/slide-deck pairs from recent *ACL conferences, we build four persona-aware configurations, then present Persona-Aware-D2S, which finetunes LLMs with target-audience feedback. Automated metrics and human evaluation show the model produces presentations that are informative and tailored to the expectations and cognitive abilities of the target audience.
SMART-Editor: A Multi-Agent Framework for Human-Like Design Editing with Structural Integrity Findings of EACL 2026
Despite progress in natural-image editing with MLLMs, compositional layout and content editing for structured visual domains (posters, websites) remains under-explored. SMART-Editor is a multi-agent framework for compositional editing of structured images. Unlike prior models focused on isolated local edits, it maintains global coherence through two complementary strategies: Reward-Refine, an inference-time reward-guided refinement method, and Reward-DPO, a training-time preference-optimization approach over reward-aligned layout pairs. We introduce SMART-Edit-Bench, a benchmark of cascading multi-step edits that require layout- and semantics-preserving reasoning about edit order.
Human-centered evaluation6 papers
Measuring whether an artifact actually helped a person, rather than whether it resembles a reference.
From Fluent to Useful: Generative AI That Models Purpose, Audience, and Presenter for Scientific Communication ACL 2026 SRW Thesis proposal
Modern generative AI produces fluent text, polished slides, and clean diagrams, yet still fails when an artifact must serve a specific purpose for a specific reader, used by a specific presenter. The missing piece is not fluency but a model of why content is being produced, for whom, and how it should adapt as goals shift. This proposal reviews five completed systems across the scientific communication pipeline and sets out three directions: a goal-driven framework measuring the educational utility of document-to-video generation, presenter-side personalization that treats the presenter as a first-class user, and a unified benchmark for transferable user preferences.
Is your benchmark truly adversarial? AdvScore: Evaluating Human-Grounded Adversarialness NAACL 2025 Outstanding Paper Award
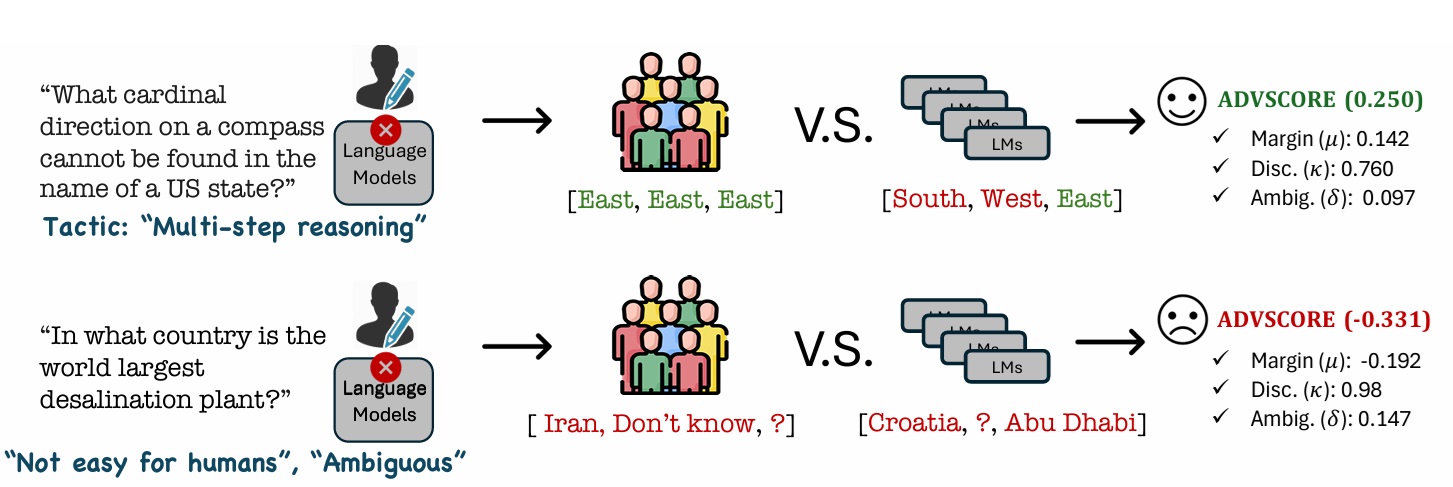
Adversarial datasets should validate AI robustness with samples humans handle well but models do not — yet as models evolve, datasets become obsolete, and there is no standardized metric for measuring how adversarial a dataset remains. We propose ADVSCORE, a human-grounded metric that captures models' and humans' varying abilities while identifying poor examples, and use it to drive a dataset-creation pipeline yielding ADVQA. Applying it across 9,347 human responses and ten models' predictions over 2020–2024, we track model improvement and give guidance for achieving robustness comparable to human capability.
PEDANTS: Cheap but Effective and Interpretable Answer Equivalence Findings of EMNLP 2024
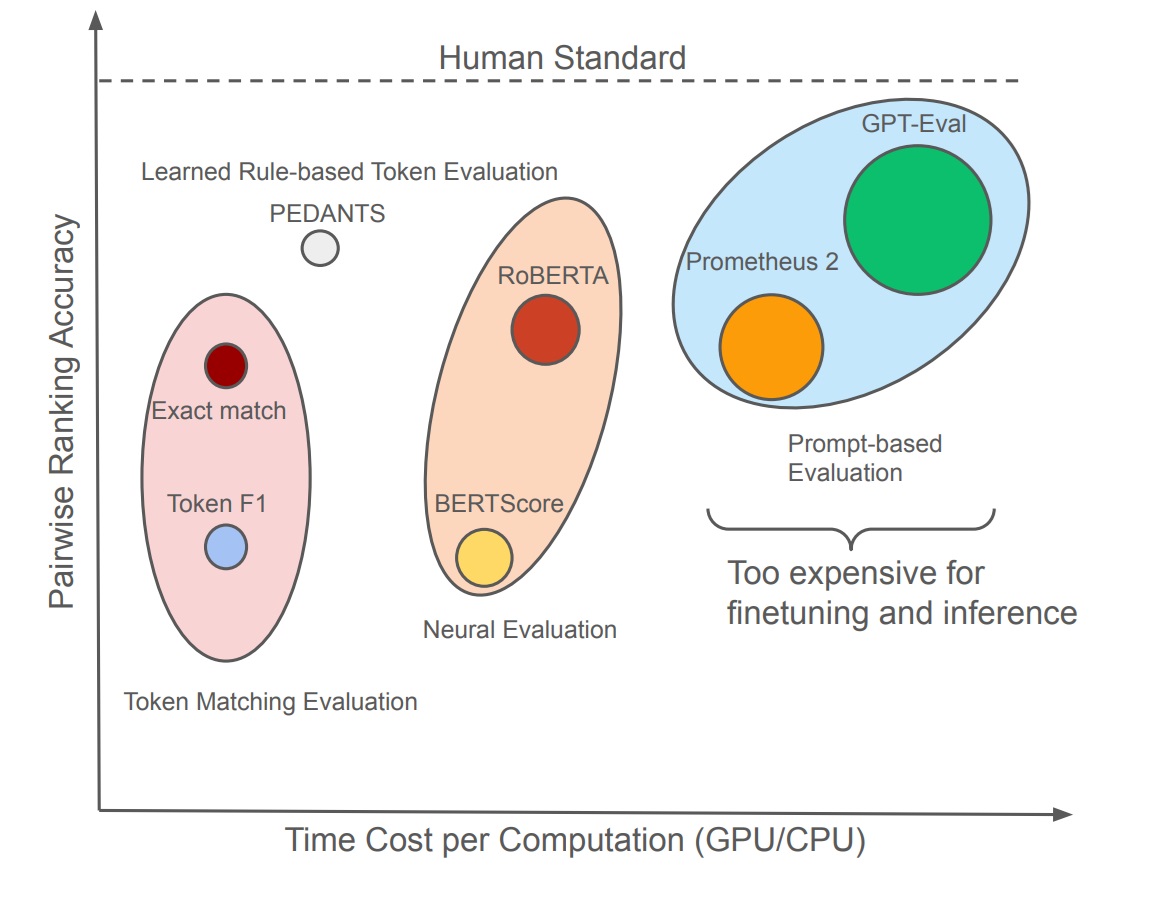
Question answering only progresses if we can tell whether an answer is correct, but current answer-correctness metrics struggle with the verbose, free-form answers of LLMs. Two challenges dominate short-form QA evaluation: a lack of diverse evaluation data and over-reliance on expensive, slow LLM scorers. We provide rubrics and datasets adopted from the trivia community and propose an efficient, interpretable QA evaluation that is more stable than exact match and neural methods such as BERTScore.
A Good Talk Doesn't Look Like a Summary, It Teaches You! Measuring Takeaways from Paper-to-Video Generation arXiv 2026
Automatically generated videos from scientific papers are increasingly used for education and research dissemination, but existing evaluation metrics measure visual quality or whether key points appear — not whether the video helps viewers understand. We introduce EffectivePresentationScorer, a framework for evaluating instructional quality: whether a video explains the main ideas clearly, introduces needed background concepts, and connects technical details to the paper's contribution. Applied to existing paper-to-video systems, it finds that generated videos mention the correct topics and follow the paper's structure but fail to explain prerequisite concepts or clarify why the method works.
Large Language Models are Effective Human Annotation Assistants, But Not Good Independent Annotators Findings of ACL 2026
Event annotation matters for identifying market changes, monitoring breaking news, and understanding sociological trends, but expert coding is expensive. Unlike experiments focused on single contexts, we evaluate a holistic workflow that removes irrelevant documents, merges documents about the same event, and annotates events. LLM-based automated annotation beats TF-IDF baselines but remains unreliable compared to human experts. Using LLMs to assist experts, however, reduces the time and mental effort of variable annotation, and annotators agree more with LLM-extracted variables than with fully automated LLM annotation.
Benchmarked Yet Not Measured — Generative AI Should be Evaluated Against Real-World Utility arXiv 2026
Generative AI systems achieve impressive benchmark performance yet fail to deliver real-world utility — a disconnect we identify across 28 deployment cases spanning education, healthcare, software engineering, and law. We argue this benchmark–utility gap arises from three recurring failures in evaluation practice: proxy displacement, temporal collapse, and distributional concealment. We propose SCU-GenEval, a four-stage framework covering stakeholder-goal mapping, construct-indicator specification, mechanism modeling, and longitudinal utility measurement, supported by structured deployment protocols, context-conditioned user simulators, and goal-conditioned proxy metrics.
Uncovering people from interactions, and aligning to their needs4 papers
Recovering intent, expertise, and mental models from the traces of how people work — edits, comments, critiques, preferences — rather than from explicit labels.
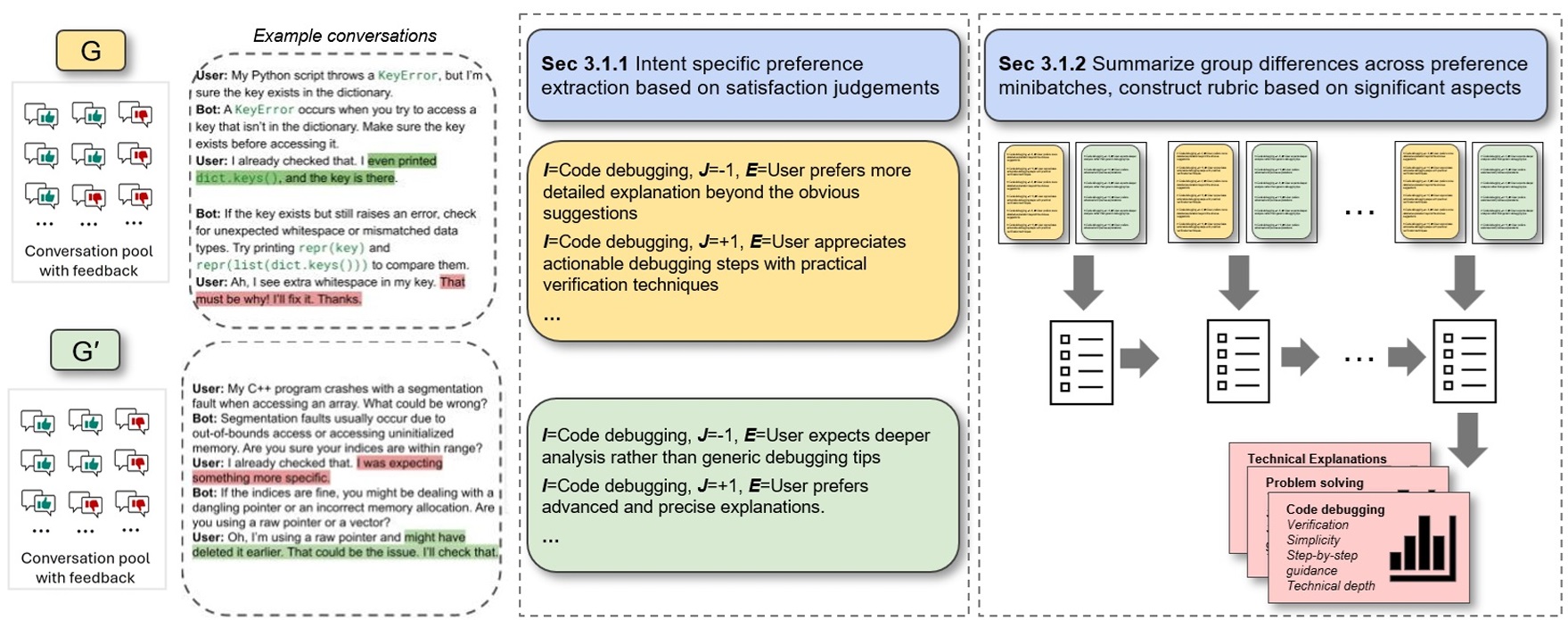
Group Preference Alignment: Customized LLM Response Generation from In-Situ Conversations EMNLP 2025 (Industry Track)
LLMs often fail to meet the specialized needs of distinct user groups due to their one-size-fits-all training paradigm. We propose Group Preference Alignment (GPA), a group-aware framework with two steps: Group-Aware Preference Extraction, where maximally divergent user-group preferences are mined from real conversation logs and distilled into interpretable rubrics; and tailored response generation via either Context-Tuned Inference (GPA-CT) or Rubric-Finetuning Inference (GPA-FT). Crucially, when groups agree on an intent the rubric is empty and no personalization fires — over-personalizing where preferences already align is itself a failure mode.
Adaptive IE: Investigating the Complementarity of Human–AI Collaboration to Adaptively Extract Information On-the-Fly COLING 2025 Oral
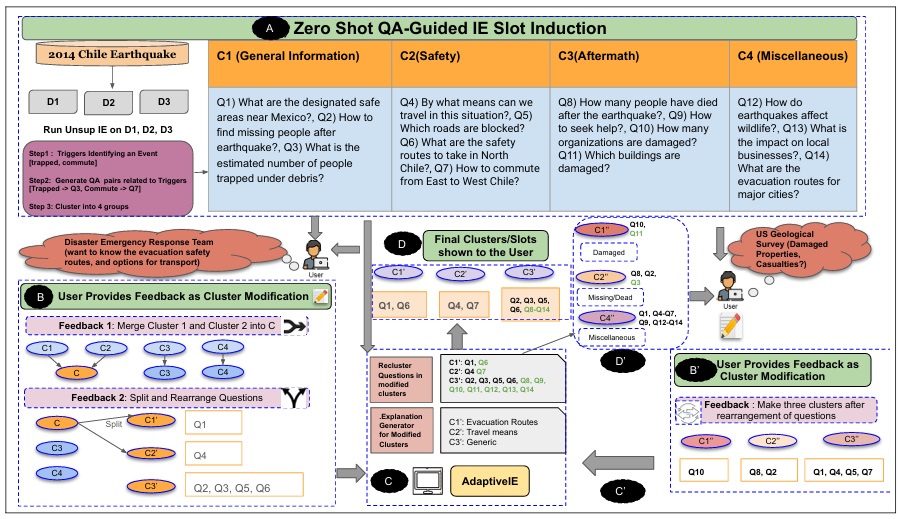
Information-extraction needs vary over time, so a flexible IE system is valuable — yet existing systems are either fully supervised (expensive annotation) or fully unsupervised (output that ignores user needs). We formally introduce "IE on-the-fly" and address it with Adaptive IE, which uses human-in-the-loop refinement to adapt to changing user questions. Through human experiments on three diverse datasets, we show Adaptive IE is a domain-agnostic, responsive, and efficient framework that helps users access useful information while quickly reorganizing it in response to evolving needs.
Learning User Mental Models for Personalized Creation and Collaborative Work Splitting Ongoing work
When and Where Does Personalization Help and Hurt? Modelling People's Needs from Longitudinal Traces Ongoing work
Multimodal world state2 papers
Keeping physical and social state coherent — objects, layouts, constraints, gestures, roles — across long, multi-turn generation and editing.
CANVAS: Continuity-Aware Narratives via Visual Agentic Storyboard Generation arXiv 2026
Long-form visual storytelling requires maintaining continuity across shots: consistent characters, stable environments, and smooth transitions. Existing generative models produce strong individual frames but fail to preserve continuity. We introduce CANVAS, a multi-agent framework that explicitly plans visual continuity in multi-shot narratives through character continuity, persistent background anchors, and location-aware scene planning. Evaluated on ST-Bench and ViStoryBench plus a new HardContinuityBench, CANVAS improves background continuity by 21.6%, character consistency by 9.6%, and prop consistency by 7.6% over the best baseline.
Correlating Instruction-Tuning (in Multimodal Models) with Vision-Language Processing (in the Brain) ICLR 2025
Instruction-tuned multimodal LLMs show stronger alignment with brain activity during natural-scene viewing than vision-only models, especially when processing task-specific instructions like image captioning and visual question answering. However, not all instructions contribute equally to brain alignment, highlighting the need for more precise instruction encoding to better predict neural responses.
Teaching, Mentoring & Service
Coverage is not comprehension. My research on evaluation asks whether an artifact actually taught anyone anything, and I hold my teaching to the same standard. Each of these has its own page.
Teaching →
Six course appointments spanning first-year programming through graduate deep learning, assessment design for a national open-enrollment course, and the courses I would build.
Mentoring →
How I work with student researchers, the students I have worked with, and the mentors I learned it from.
Academic service →
Workshop organization, program committees, ACL Rolling Review, and two weekly reading groups I have run since 2021.